llama.cpp guide - Running LLMs locally, on any hardware, from scratch
Table of Contents
No LLMs were harmed during creation of this post.
so, i started playing with LLMs…#
…and it’s pretty fun. I was very skeptical about the AI/LLM “boom” back when it started. I thought, like many other people, that they are just mostly making stuff up, and generating uncanny-valley-tier nonsense. Boy, was i wrong. I’ve used ChatGPT once or twice, to test the waters - it made a pretty good first impression, despite hallucinating a bit. That was back when GPT3.5 was the top model. We came a pretty long way since then.
However, despite ChatGPT not disappointing me, i was still skeptical. Everything i’ve wrote, and every piece of response was fully available to OpenAI, or whatever other provider i’d want to use. This is not a big deal, but it tickles me in a wrong way, and also means i can’t use LLMs for any work-related non-open-source stuff. Also, ChatGPT is free only to a some degree - if i’d want to go full-in on AI, i’d probably have to start paying. Which, obviously, i’d rather avoid.
At some point i started looking at open-source models. I had no idea how to use them, but the moment i saw the sizes of “small” models, like Llama 2 7B, i’ve realized that my RTX 2070 Super with mere 8GB of VRAM would probably have issues running them (i was wrong on that too!), and running them on CPU would probably yield very bad performance. And then, i’ve bought a new GPU - RX 7900 XT, with 20GB of VRAM, which is definitely more than enough to run small-to-medium LLMs. Yay!
Now my issue was finding some software that could run an LLM on that GPU.
CUDA was the most popular back-end - but that’s for NVidia GPUs, not AMD.
After doing a bit of research, i’ve found out about ROCm and found LM Studio.
And this was exactly what i was looking for - at least for the time being.
Great UI, easy access to many models, and the quantization - that was the thing that absolutely sold me into self-hosting LLMs.
Existence of quantization made me realize that you don’t need powerful hardware for running LLMs!
You can even run LLMs on RaspberryPi’s at this point (with llama.cpp too!)
Of course, the performance will be abysmal if you don’t run the LLM with a proper backend on a decent hardware, but the bar is currently not very high.
If you came here with intention of finding some piece of software that will allow you to easily run popular models on most modern hardware for non-commercial purposes - grab LM Studio, read the next section of this post, and go play with it. It fits this description very well, just make sure to use appropriate back-end for your GPU/CPU for optimal performance.
However, if you:
- Want to learn more about
llama.cpp(which LM Studio uses as a back-end), and LLMs in general - Want to use LLMs for commercial purposes (LM Studio’s terms forbid that)
- Want to run LLMs on exotic hardware (LM Studio provides only the most popular backends)
- Don’t like closed-source software (which LM Studio, unfortunately, is) and/or don’t trust anything you don’t build yourself
- Want to have access to latest features and models as soon as possible
you should find the rest of this post pretty useful!
but first - some disclaimers for expectation management#
Before i proceed, i want to make some stuff clear. This “FAQ” answers some questions i’d like to know answers to before getting into self-hosted LLMs.
Do I need RTX 2070 Super/RX 7900 XT ot similar mid/high-end GPU to do what you did here?#
No, you don’t. I’ll elaborate later, but you can run LLMs with no GPU at all. As long as you have reasonably modern hardware (by that i mean at least a decent CPU with AVX support) - you’re compatible. But remember - your performance may vary.
What performance can I expect?#
This is a very hard question to answer directly. The speed of text generation depends on multiple factors, but primarily
- matrix operations performance on your hardware
- memory bandwidth
- model size
I’ll explain this with more details later, but you can generally get reasonable performance from the LLM by picking model small enough for your hardware. If you intend to use GPU, and it has enough memory for a model with it’s context - expect real-time text generation. In case you want to use both GPU and CPU, or only CPU - you should expect much lower performance, but real-time text generation is possible with small models.
What quality of responses can I expect?#
That heavily depends on your usage and chosen model. I can’t answer that question directly, you’ll have to play around and find out yourself. A rule of thumb is “larger the model, better the response” - consider the fact that size of SOTA (state-of-the-art) models, like GPT-4 or Claude, is usually measured in hundreds of billions of parameters. Unless you have multiple GPUs or unreasonable amount of RAM and patience - you’ll most likely be restricted to models with less than 20 billion parameters. From my experience, 7-8B models are pretty good for generic purposes and programming - and they are not very far from SOTA models like GPT-4o or Claude in terms of raw quality of generated responses, but the difference is definitely noticeable. Keep in mind that the choice of a model is only a part of the problem - providing proper context and system prompt, or fine-tuning LLMs can do wonders.
Can i replace ChatGPT/Claude/[insert online LLM provider] with that?#
Maybe. In theory - yes, but in practice - it depends on your tools.
llama.cpp provides OpenAI-compatible server.
As long as your tools communicate with LLMs via OpenAI API, and you are able to set custom endpoint, you will be able to use self-hosted LLM with them.
prerequisites#
- Reasonably modern CPU. If you’re rocking any Ryzen, or Intel’s 8th gen or newer, you’re good to go, but all of this should work on older hardware too.
- Optimally, a GPU. More VRAM, the better. If you have at least 8GB of VRAM, you should be able to run 7-8B models, i’d say that it’s reasonable minimum. Vendor doesn’t matter, llama.cpp supports NVidia, AMD and Apple GPUs (not sure about Intel, but i think i saw a backend for that - if not, Vulkan should work).
- If you’re not using GPU or it doesn’t have enough VRAM, you need RAM for the model. As above, at least 8GB of free RAM is recommended, but more is better. Keep in mind that when only GPU is used by llama.cpp, RAM usage is very low.
In the guide, i’ll assume you’re using either Windows or Linux. I can’t provide any support for Mac users, so they should follow Linux steps and consult the llama.cpp docs wherever possible.
Some context-specific formatting is used in this post:
Parts of this post where i’ll write about Windows-specific stuff will have this background. You’ll notice they’re much longer than Linux ones - Windows is a PITA. Linux is preferred. I will still explain everything step-by-step for Windows, but in case of issues - try Linux.
And parts where i’ll write about Linux-specific stuff will have this background.
building the llama#
In docs/build.md, you’ll find detailed build instructions for all the supported platforms.
By default, llama.cpp builds with auto-detected CPU support.
We’ll talk about enabling GPU and advanced CPU support later, first - let’s try building it as-is, because it’s a good baseline to start with, and it doesn’t require any external dependencies.
To do that, we only need a C++ toolchain, CMake and Ninja.
If you are very lazy, you can download a release from Github and skip building steps. Make sure to download correct version for your hardware/backend. If you have troubles picking, i recommend following the build guide anyway - it’s simple enough and should explain what you should be looking for. Keep in mind that release won’t contain Python scripts that we’re going to use, so if you’ll want to quantize models manually, you’ll need to get them from repository.
On Windows, i recommend using MSYS to setup the environment for building and using llama.cpp.
Microsoft Visual C++ is supported too, but trust me on that - you’ll want to use MSYS instead (it’s still a bit of pain in the ass, Linux setup is much simpler).
Follow the guide on the main page to install MinGW for x64 UCRT environment, which you probably should be using.
CMake, Ninja and Git can be installed in UCRT MSYS environment like that:
pacman -S git mingw-w64-ucrt-x86_64-cmake mingw-w64-ucrt-x86_64-ninja
However, if you’re using any other toolchain (MSVC, or non-MSYS one), you should install CMake, Git and Ninja via winget:
winget install cmake git.git ninja-build.ninja
You’ll also need Python, which you can get via winget. Get the latest available version, at the time of writing this post it’s 3.13.
DO NOT USE PYTHON FROM MSYS, IT WILL NOT WORK PROPERLY DUE TO ISSUES WITH BUILDING llama.cpp DEPENDENCY PACKAGES!
We’re going to be using MSYS only for building llama.cpp, nothing more.
If you’re using MSYS, remember to add it’s /bin (C:\msys64\ucrt64\bin by default) directory to PATH, so Python can use MinGW for building packages.
Check if GCC is available by opening PowerShell/Command line and trying to run gcc --version.
Also; check if it’s correct GCC by running where.exe gcc.exe and seeing where the first entry points to.
Reorder your PATH if you’ll notice that you’re using wrong GCC.
If you’re using MSVC - ignore this disclaimer, it should be “detectable” by default.
winget install python.python.3.13
I recommend installing/upgrading pip, setuptools and wheel packages before continuing.
python -m pip install --upgrade pip wheel setuptools
On Linux, GCC is recommended, but you should be able to use Clang if you’d prefer by setting CMAKE_C_COMPILER=clang and CMAKE_CXX_COMPILER=clang++ variables.
You should have GCC preinstalled (check gcc --version in terminal), if not - get latest version for your distribution using your package manager.
Same applies to CMake, Ninja, Python 3 (with setuptools, wheel and pip) and Git.
Let’s start by grabbing a copy of llama.cpp source code, and moving into it.
Disclaimer: this guide assumes all commands are ran from user’s home directory (
/home/[yourusername]on Linux,C:/Users/[yourusername]on Windows). You can use any directory you’d like, just keep in mind that if “starting directory” is not explicitly mentioned, start from home dir/your chosen one.
If you’re using MSYS, remember that MSYS home directory is different from Windows home directory. Make sure to use
cd(without arguments) to move into it after starting MSYS.
(If you have previously configured SSH auth w/ GitHub, use git@github.com:ggerganov/llama.cpp.git instead of the URL below)
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
git submodule update --init --recursive
Now we’ll use CMake to generate build files, build the project, and install it.
Run the following command to generate build files in build/ subdirectory:
cmake -S . -B build -G Ninja -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/your/install/dir -DLLAMA_BUILD_TESTS=OFF -DLLAMA_BUILD_EXAMPLES=ON -DLLAMA_BUILD_SERVER=ON
There’s a lot of CMake variables being defined, which we could ignore and let llama.cpp use it’s defaults, but we won’t:
CMAKE_BUILD_TYPEis set to release for obvious reasons - we want maximum performance.CMAKE_INSTALL_PREFIXis where thellama.cppbinaries and python scripts will go. Replace the value of this variable, or remove it’s definition to keep default value.- On Windows, default directory is
c:/Program Files/llama.cpp. As above, you’ll need admin privileges to install it, and you’ll have to add thebin/subdirectory to yourPATHto make llama.cpp binaries accessible system-wide. I prefer installing llama.cpp in$env:LOCALAPPDATA/llama.cpp(C:/Users/[yourusername]/AppData/Local/llama.cpp), as it doesn’t require admin privileges. - On Linux, default directory is
/usr/local. You can ignore this variable if that’s fine with you, but you’ll need superuser permissions to install the binaries there. If you don’t have them, change it to point somewhere in your user directory and add it’sbin/subdirectory toPATH.
- On Windows, default directory is
LLAMA_BUILD_TESTSis set toOFFbecause we don’t need tests, it’ll make the build a bit quicker.LLAMA_BUILD_EXAMPLESisONbecause we’re gonna be using them.LLAMA_BUILD_SERVER- see above. Note: DisablingLLAMA_BUILD_EXAMPLESunconditionally disables building the server, both must beON.
If you’d ignore all of those variables, the default would be used - in case of LLAMA_BUILD_* variables, all of those is ON (if you’re building llama.cpp as standalone app, which you most likely are).
CMAKE_BUILD_TYPE is usually set to Release by default, but not always, so i’d rather set it manually.
CMAKE_INSTALL_PREFIX is not necessary at all if you don’t intend to install the executables and you’re fine with adding the build dir’s /bin subdirectory to PATH.
Now, let’s build the project.
Replace X with amount of cores your CPU has for faster compilation.
In theory, Ninja should automatically use all available cores, but i still prefer passing this argument manually.
cmake --build build --config Release -j X
Building should take only a few minutes. After that, we can install the binaries for easier usage.
cmake --install build --config Release
Now, after going to CMAKE_INSTALL_PREFIX/bin directory, we should see a list of executables and Python scripts:
/c/Users/phoen/llama-build/bin
❯ l
Mode Size Date Modified Name
-a--- 203k 7 Nov 16:14 convert_hf_to_gguf.py
-a--- 3.9M 7 Nov 16:18 llama-batched-bench.exe
-a--- 3.9M 7 Nov 16:18 llama-batched.exe
-a--- 3.4M 7 Nov 16:18 llama-bench.exe
-a--- 3.9M 7 Nov 16:18 llama-cli.exe
-a--- 3.2M 7 Nov 16:18 llama-convert-llama2c-to-ggml.exe
-a--- 3.9M 7 Nov 16:18 llama-cvector-generator.exe
-a--- 3.9M 7 Nov 16:18 llama-embedding.exe
-a--- 3.9M 7 Nov 16:18 llama-eval-callback.exe
-a--- 3.9M 7 Nov 16:18 llama-export-lora.exe
-a--- 3.0M 7 Nov 16:18 llama-gbnf-validator.exe
-a--- 1.2M 7 Nov 16:18 llama-gguf-hash.exe
-a--- 3.0M 7 Nov 16:18 llama-gguf-split.exe
-a--- 1.1M 7 Nov 16:18 llama-gguf.exe
-a--- 3.9M 7 Nov 16:18 llama-gritlm.exe
-a--- 3.9M 7 Nov 16:18 llama-imatrix.exe
-a--- 3.9M 7 Nov 16:18 llama-infill.exe
-a--- 4.2M 7 Nov 16:18 llama-llava-cli.exe
-a--- 3.9M 7 Nov 16:18 llama-lookahead.exe
-a--- 3.9M 7 Nov 16:18 llama-lookup-create.exe
-a--- 1.2M 7 Nov 16:18 llama-lookup-merge.exe
-a--- 3.9M 7 Nov 16:18 llama-lookup-stats.exe
-a--- 3.9M 7 Nov 16:18 llama-lookup.exe
-a--- 4.1M 7 Nov 16:18 llama-minicpmv-cli.exe
-a--- 3.9M 7 Nov 16:18 llama-parallel.exe
-a--- 3.9M 7 Nov 16:18 llama-passkey.exe
-a--- 4.0M 7 Nov 16:18 llama-perplexity.exe
-a--- 3.0M 7 Nov 16:18 llama-quantize-stats.exe
-a--- 3.2M 7 Nov 16:18 llama-quantize.exe
-a--- 3.9M 7 Nov 16:18 llama-retrieval.exe
-a--- 3.9M 7 Nov 16:18 llama-save-load-state.exe
-a--- 5.0M 7 Nov 16:19 llama-server.exe
-a--- 3.0M 7 Nov 16:18 llama-simple-chat.exe
-a--- 3.0M 7 Nov 16:18 llama-simple.exe
-a--- 3.9M 7 Nov 16:18 llama-speculative.exe
-a--- 3.1M 7 Nov 16:18 llama-tokenize.exe
Don’t feel overwhelmed by the amount, we’re only going to be using few of them.
You should try running one of them to check if the executables have built correctly, for example - try llama-cli --help.
We can’t do anything meaningful yet, because we lack a single critical component - a model to run.
getting a model#
The main place to look for models is HuggingFace. You can also find datasets and other AI-related stuff there, great site.
We’re going to use SmolLM2 here, a model series created by HuggingFace and published fairly recently (1st November 2024).
The reason i’ve chosen this model is the size - as the name implies, it’s small.
Largest model from this series has 1.7 billion parameters, which means that it requires approx. 4GB of system memory to run in raw, unquantized form (excluding context)!
There are also 360M and 135M variants, which are even smaller and should be easily runnable on RaspberryPi or a smartphone.
There’s but one issue - llama.cpp cannot run “raw” models directly.
What is usually provided by most LLM creators are original weights in .safetensors or similar format.
llama.cpp expects models in .gguf format.
Fortunately, there is a very simple way of converting original model weights into .gguf - llama.cpp provides convert_hf_to_gguf.py script exactly for this purpose!
Sometimes the creator provides .gguf files - for example, two variants of SmolLM2 are provided by HuggingFace in this format.
This is not a very common practice, but you can also find models in .gguf format uploaded there by community.
However, i’ll ignore the existence of pre-quantized .gguf files here, and focus on quantizing our models by ourselves here, as it’ll allow us to experiment and adjust the quantization parameters of our model without having to download it multiple times.
Grab the content of SmolLM2 1.7B Instruct repository (you can use 360M Instruct or 135M Instruct version instead, if you have less than 4GB of free (V)RAM - or use any other model you’re already familiar with, if it supports transformers), but omit the LFS files - we only need a single one, and we’ll download it manually.
Why Instruct, specifically? You might have noticed that there are two variants of all those models - Instruct and the other one without a suffix. Instruct is trained for chat conversations, base model is only trained for text completion and is usually used as a base for further training. This rule applies to most LLMs, but not all, so make sure to read the model’s description before using it!
If you’re using Bash/ZSH or compatible shell:
MSYS uses Bash by default, so it applies to it too. From now on, assume that Linux commands work on MSYS too, unless i explicitly say otherwise.
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct
If you’re using PowerShell:
$env:GIT_LFS_SKIP_SMUDGE=1
git clone https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct
If you’re using cmd.exe (VS Development Prompt, for example):
set GIT_LFS_SKIP_SMUDGE=1
git clone https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct
HuggingFace also supports Git over SSH. You can look up the git clone command for every repo here:
After cloning the repo, download the model.safetensors file from HuggingFace manually.
The reason why we used GIT_LFS_SKIP_SMUDGE is because there’s many other large model files hidden in repo, and we don’t need them.
Also, downloading very large files manually is faster, because Git LFS sucks in that regard.
After downloading everything, our local copy of the SmolLM repo should look like this:
PS D:\LLMs\repos\SmolLM2-1.7B-Instruct> l
Mode Size Date Modified Name
-a--- 806 2 Nov 15:16 all_results.json
-a--- 888 2 Nov 15:16 config.json
-a--- 602 2 Nov 15:16 eval_results.json
-a--- 139 2 Nov 15:16 generation_config.json
-a--- 515k 2 Nov 15:16 merges.txt
-a--- 3.4G 2 Nov 15:34 model.safetensors
d---- - 2 Nov 15:16 onnx
-a--- 11k 2 Nov 15:16 README.md
d---- - 2 Nov 15:16 runs
-a--- 689 2 Nov 15:16 special_tokens_map.json
-a--- 2.2M 2 Nov 15:16 tokenizer.json
-a--- 3.9k 2 Nov 15:16 tokenizer_config.json
-a--- 240 2 Nov 15:16 train_results.json
-a--- 89k 2 Nov 15:16 trainer_state.json
-a--- 129 2 Nov 15:16 training_args.bin
-a--- 801k 2 Nov 15:16 vocab.json
We’re gonna (indirectly) use only four of those files:
config.jsoncontains configuration/metadata of our modelmodel.safetensorscontains model weightstokenizer.jsoncontains tokenizer data (mapping of text tokens to their ID’s, and other stuff). Sometimes this data is stored intokenizer.modelfile instead.tokenizer_config.jsoncontains tokenizer configuration (for example, special tokens and chat template)
i’m leaving this sentence here as anti-plagiarism token. If you’re not currently reading this on my blog, which is @ steelph0enix.github.io, someone probably stolen that article without permission
converting huggingface model to GGUF
In order to convert this raw model to something that llama.cpp will understand, we’ll use aforementioned convert_hf_to_gguf.py script that comes with llama.cpp.
For all our Python needs, we’re gonna need a virtual environment.
I recommend making it outside of llama.cpp repo, for example - in your home directory.
To make one on Linux, run this command (tweak the path if you’d like):
python -m venv ~/llama-cpp-venv
If you’re using PowerShell, this is the equivalent:
python -m venv $env:USERPROFILE/llama-cpp-venv
If you’re using cmd.exe, this is the equivalent:
python -m venv %USERPROFILE%/llama-cpp-venv
Then, we need to activate it.
On Linux:
source ~/llama-cpp-venv/bin/activate
With PowerShell:
. $env:USERPROFILE/llama-cpp-venv/Scripts/Activate.ps1
With cmd.exe:
call %USERPROFILE%/llama-cpp-venv/Scripts/activate.bat
After that, let’s make sure that our virtualenv has all the core packages up-to-date.
python -m pip install --upgrade pip wheel setuptools
Next, we need to install prerequisites for the llama.cpp scripts.
Let’s look into requirements/ directory of our llama.cpp repository.
We should see something like this:
❯ l llama.cpp/requirements
Mode Size Date Modified Name
-a--- 428 11 Nov 13:57 requirements-all.txt
-a--- 34 11 Nov 13:57 requirements-compare-llama-bench.txt
-a--- 111 11 Nov 13:57 requirements-convert_hf_to_gguf.txt
-a--- 111 11 Nov 13:57 requirements-convert_hf_to_gguf_update.txt
-a--- 99 11 Nov 13:57 requirements-convert_legacy_llama.txt
-a--- 43 11 Nov 13:57 requirements-convert_llama_ggml_to_gguf.txt
-a--- 96 11 Nov 13:57 requirements-convert_lora_to_gguf.txt
-a--- 48 11 Nov 13:57 requirements-pydantic.txt
-a--- 13 11 Nov 13:57 requirements-test-tokenizer-random.txt
As we can see, there’s a file with deps for our script! To install dependencies from it, run this command:
python -m pip install --upgrade -r llama.cpp/requirements/requirements-convert_hf_to_gguf.txt
If pip failed during build, make sure you have working C/C++ toolchain in your PATH.
If you’re using MSYS for that, don’t. Go back to PowerShell/cmd, install Python via winget and repeat the setup. As far as i’ve tested it, Python deps don’t detect the platform correctly on MSYS and try to use wrong build config. This is what i warned you about earlier.
Now we can use the script to create our GGUF model file. Start with printing the help and reading the options.
python llama.cpp/convert_hf_to_gguf.py --help
If this command printed help, you can continue.
Otherwise make sure that python’s virtualenv is active and dependencies are correctly installed, and try again.
To convert our model we can simply pass the path to directory with model’s repository and, optionally, path to output file.
We don’t need to tweak the quantization here, for maximum flexibility we’re going to create a floating-point GGUF file which we’ll then quantize down.
That’s because llama-quantize offers much more quantization options, and this script picks optimal floating-point format by default.
To create GGUF file from our downloaded HuggingFace repository with SmolLM2 (Replace SmolLM2-1.7B-Instruct with your path, if it’s different) run this command:
python llama.cpp/convert_hf_to_gguf.py SmolLM2-1.7B-Instruct --outfile ./SmolLM2.gguf
If everything went correctly, you should see similar output:
INFO:hf-to-gguf:Loading model: SmolLM2-1.7B-Instruct
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:hf-to-gguf:Exporting model...
INFO:hf-to-gguf:gguf: loading model part 'model.safetensors'
INFO:hf-to-gguf:token_embd.weight, torch.bfloat16 --> F16, shape = {2048, 49152}
INFO:hf-to-gguf:blk.0.attn_norm.weight, torch.bfloat16 --> F32, shape = {2048}
...
INFO:hf-to-gguf:blk.9.attn_q.weight, torch.bfloat16 --> F16, shape = {2048, 2048}
INFO:hf-to-gguf:blk.9.attn_v.weight, torch.bfloat16 --> F16, shape = {2048, 2048}
INFO:hf-to-gguf:output_norm.weight, torch.bfloat16 --> F32, shape = {2048}
INFO:hf-to-gguf:Set meta model
INFO:hf-to-gguf:Set model parameters
INFO:hf-to-gguf:gguf: context length = 8192
INFO:hf-to-gguf:gguf: embedding length = 2048
INFO:hf-to-gguf:gguf: feed forward length = 8192
INFO:hf-to-gguf:gguf: head count = 32
INFO:hf-to-gguf:gguf: key-value head count = 32
INFO:hf-to-gguf:gguf: rope theta = 130000
INFO:hf-to-gguf:gguf: rms norm epsilon = 1e-05
INFO:hf-to-gguf:gguf: file type = 1
INFO:hf-to-gguf:Set model tokenizer
INFO:gguf.vocab:Adding 48900 merge(s).
INFO:gguf.vocab:Setting special token type bos to 1
INFO:gguf.vocab:Setting special token type eos to 2
INFO:gguf.vocab:Setting special token type unk to 0
INFO:gguf.vocab:Setting special token type pad to 2
INFO:gguf.vocab:Setting chat_template to {% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system
You are a helpful AI assistant named SmolLM, trained by Hugging Face<|im_end|>
' }}{% endif %}{{'<|im_start|>' + message['role'] + '
' + message['content'] + '<|im_end|>' + '
'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant
' }}{% endif %}
INFO:hf-to-gguf:Set model quantization version
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:SmolLM2.gguf: n_tensors = 218, total_size = 3.4G
Writing: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3.42G/3.42G [00:15<00:00, 215Mbyte/s]
INFO:hf-to-gguf:Model successfully exported to SmolLM2.gguf
quantizing the model#
Now we can finally quantize our model!
To do that, we’ll use llama-quantize executable that we previously compiled with other llama.cpp executables.
First, let’s check what quantizations we have available.
llama-quantize --help
As of now, llama-quantize --help shows following types:
usage: llama-quantize [--help] [--allow-requantize] [--leave-output-tensor] [--pure] [--imatrix] [--include-weights] [--exclude-weights] [--output-tensor-type] [--token-embedding-type] [--override-kv] model-f32.gguf [model-quant.gguf] type [nthreads]
...
Allowed quantization types:
2 or Q4_0 : 4.34G, +0.4685 ppl @ Llama-3-8B
3 or Q4_1 : 4.78G, +0.4511 ppl @ Llama-3-8B
8 or Q5_0 : 5.21G, +0.1316 ppl @ Llama-3-8B
9 or Q5_1 : 5.65G, +0.1062 ppl @ Llama-3-8B
19 or IQ2_XXS : 2.06 bpw quantization
20 or IQ2_XS : 2.31 bpw quantization
28 or IQ2_S : 2.5 bpw quantization
29 or IQ2_M : 2.7 bpw quantization
24 or IQ1_S : 1.56 bpw quantization
31 or IQ1_M : 1.75 bpw quantization
36 or TQ1_0 : 1.69 bpw ternarization
37 or TQ2_0 : 2.06 bpw ternarization
10 or Q2_K : 2.96G, +3.5199 ppl @ Llama-3-8B
21 or Q2_K_S : 2.96G, +3.1836 ppl @ Llama-3-8B
23 or IQ3_XXS : 3.06 bpw quantization
26 or IQ3_S : 3.44 bpw quantization
27 or IQ3_M : 3.66 bpw quantization mix
12 or Q3_K : alias for Q3_K_M
22 or IQ3_XS : 3.3 bpw quantization
11 or Q3_K_S : 3.41G, +1.6321 ppl @ Llama-3-8B
12 or Q3_K_M : 3.74G, +0.6569 ppl @ Llama-3-8B
13 or Q3_K_L : 4.03G, +0.5562 ppl @ Llama-3-8B
25 or IQ4_NL : 4.50 bpw non-linear quantization
30 or IQ4_XS : 4.25 bpw non-linear quantization
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 4.37G, +0.2689 ppl @ Llama-3-8B
15 or Q4_K_M : 4.58G, +0.1754 ppl @ Llama-3-8B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 5.21G, +0.1049 ppl @ Llama-3-8B
17 or Q5_K_M : 5.33G, +0.0569 ppl @ Llama-3-8B
18 or Q6_K : 6.14G, +0.0217 ppl @ Llama-3-8B
7 or Q8_0 : 7.96G, +0.0026 ppl @ Llama-3-8B
33 or Q4_0_4_4 : 4.34G, +0.4685 ppl @ Llama-3-8B
34 or Q4_0_4_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
35 or Q4_0_8_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
1 or F16 : 14.00G, +0.0020 ppl @ Mistral-7B
32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B
0 or F32 : 26.00G @ 7B
COPY : only copy tensors, no quantizing
Let’s decode this table.
From the left, we have IDs and names of quantization types - you can use either when calling llama-quantize.
After the :, there’s a short description that in most cases shows either the example model’s size and perplexity, or the amount of bits per tensor weight (bpw) for that specific quantization.
Perplexity is a metric that describes how certain the model is about it’s predictions.
We can think about it like that: lower perplexity -> model is more certain about it’s predictions -> model is more accurate.
This is a daily reminder that LLMs are nothing more than overcomplicated autocompletion algorithms.
The “bits per weight” metric tells us the average size of quantized tensor’s weight.
You may think it’s strange that those are floating-point values, but we’ll see the reason for that soon.
Now, the main question that needs to be answered is “which quantization do we pick?”. And the answer is “it depends”. My rule of thumb for picking quantization type is “the largest i can fit in my VRAM, unless it’s too slow for my taste” and i recommend this approach if you don’t know where to start! Obviously, if you don’t have/want to use GPU, replace “VRAM” with “RAM” and “largest i can fit” with “largest i can fit without forcing the OS to move everything to swap”. That creates another question - “what is the largest quant i can fit in my (V)RAM”? And this depends on the original model’s size and encoding, and - obviously - the amount of (V)RAM you have. Since we’re using SmolLM2, our model is relatively small. GGUF file of 1.7B-Instruct variant in BF16 format weights 3.4GB. Most models you’ll encounter will be encoded in either BF16 or FP16 format, rarely we can find FP32-encoded LLMs. That means most of models have 16 bits per weight by default. We can easily approximate the size of quantized model by multiplying the original size with approximate ratio of bits per weight. For example, let’s assume we want to know how large will SmolLM2 1.7B-Instruct be after Q8_0 quantization. Let’s assume Q8_0 quant uses 8 bits per word, which means the ratio is simply 1/2, so our model should weight ~1.7GB. Let’s check that!
The first argument is source model, second - target file.
Third is the quantization type, and last is the amount of cores for parallel processing.
Replace N with amount of cores in your system and run this command:
llama-quantize SmolLM2.gguf SmolLM2.q8.gguf Q8_0 N
You should see similar output:
main: build = 4200 (46c69e0e)
main: built with gcc (GCC) 14.2.1 20240910 for x86_64-pc-linux-gnu
main: quantizing 'SmolLM2.gguf' to 'SmolLM2.q8.gguf' as Q8_0 using 24 threads
llama_model_loader: loaded meta data with 37 key-value pairs and 218 tensors from SmolLM2.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = SmolLM2 1.7B Instruct
llama_model_loader: - kv 3: general.finetune str = Instruct
llama_model_loader: - kv 4: general.basename str = SmolLM2
llama_model_loader: - kv 5: general.size_label str = 1.7B
llama_model_loader: - kv 6: general.license str = apache-2.0
llama_model_loader: - kv 7: general.base_model.count u32 = 1
llama_model_loader: - kv 8: general.base_model.0.name str = SmolLM2 1.7B
llama_model_loader: - kv 9: general.base_model.0.organization str = HuggingFaceTB
llama_model_loader: - kv 10: general.base_model.0.repo_url str = https://huggingface.co/HuggingFaceTB/...
llama_model_loader: - kv 11: general.tags arr[str,4] = ["safetensors", "onnx", "transformers...
llama_model_loader: - kv 12: general.languages arr[str,1] = ["en"]
llama_model_loader: - kv 13: llama.block_count u32 = 24
llama_model_loader: - kv 14: llama.context_length u32 = 8192
llama_model_loader: - kv 15: llama.embedding_length u32 = 2048
llama_model_loader: - kv 16: llama.feed_forward_length u32 = 8192
llama_model_loader: - kv 17: llama.attention.head_count u32 = 32
llama_model_loader: - kv 18: llama.attention.head_count_kv u32 = 32
llama_model_loader: - kv 19: llama.rope.freq_base f32 = 130000.000000
llama_model_loader: - kv 20: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 21: general.file_type u32 = 32
llama_model_loader: - kv 22: llama.vocab_size u32 = 49152
llama_model_loader: - kv 23: llama.rope.dimension_count u32 = 64
llama_model_loader: - kv 24: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 25: tokenizer.ggml.pre str = smollm
llama_model_loader: - kv 26: tokenizer.ggml.tokens arr[str,49152] = ["<|endoftext|>", "<|im_start|>", "<|...
llama_model_loader: - kv 27: tokenizer.ggml.token_type arr[i32,49152] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
llama_model_loader: - kv 28: tokenizer.ggml.merges arr[str,48900] = ["Ġ t", "Ġ a", "i n", "h e", "Ġ Ġ...
llama_model_loader: - kv 29: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 30: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 31: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 32: tokenizer.ggml.padding_token_id u32 = 2
llama_model_loader: - kv 33: tokenizer.chat_template str = {% for message in messages %}{% if lo...
llama_model_loader: - kv 34: tokenizer.ggml.add_space_prefix bool = false
llama_model_loader: - kv 35: tokenizer.ggml.add_bos_token bool = false
llama_model_loader: - kv 36: general.quantization_version u32 = 2
llama_model_loader: - type f32: 49 tensors
llama_model_loader: - type bf16: 169 tensors
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = AMD Radeon RX 7900 XT (AMD open-source driver) | uma: 0 | fp16: 1 | warp size: 64
[ 1/ 218] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
[ 2/ 218] token_embd.weight - [ 2048, 49152, 1, 1], type = bf16, converting to q8_0 .. size = 192.00 MiB -> 102.00 MiB
[ 3/ 218] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
[ 4/ 218] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
[ 5/ 218] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
[ 6/ 218] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
[ 7/ 218] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
...
[ 212/ 218] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
[ 213/ 218] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
[ 214/ 218] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
[ 215/ 218] blk.23.ffn_down.weight - [ 8192, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 32.00 MiB -> 17.00 MiB
[ 216/ 218] blk.23.ffn_gate.weight - [ 2048, 8192, 1, 1], type = bf16, converting to q8_0 .. size = 32.00 MiB -> 17.00 MiB
[ 217/ 218] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
[ 218/ 218] blk.23.ffn_up.weight - [ 2048, 8192, 1, 1], type = bf16, converting to q8_0 .. size = 32.00 MiB -> 17.00 MiB
llama_model_quantize_internal: model size = 3264.38 MB
llama_model_quantize_internal: quant size = 1734.38 MB
main: quantize time = 2289.97 ms
main: total time = 2289.97 ms
And yeah, we were more-or-less correct, it’s 1.7GB! BUT this is only the model’s size, we also have to consider the memory requirements for the context. Fortunately, context doesn’t require massive amounts of memory - i’m not really sure how much exactly it eats up, but it’s safe to assume that we should have at least 1GB memory for it. So, taking all that in account, we can approximate that to load this model to memory with the context, we need at least 3GB of free (V)RAM. This is not so bad, and most modern consumer GPUs have at least this amount (even the old GTX 1060 3GB should be able to run this model in Q8_0 quant). However, if that’s still too much, we can easily go lower! Reducing the amount of bits per weight via quantization not only reduces the model’s size, but also increases the speed of data generation. Unfortunately, it also makes the model more stupid. The change is gradual, you may not notice it when going from Q8_0 to Q6_K, but going below Q4 quant can be noticeable. I strongly recommend experimenting on your own with different models and quantization types, because your experience may be different from mine!
Oh, by the way - remember that right now our
llama.cppbuild will use CPU for calculations, so the model will reside in RAM. Make sure you have at least 3GB of free RAM before trying to use the model, if you don’t - quantize it with smaller quant, or get a smaller version.
Anyway, we got our quantized model now, we can finally use it!
running llama.cpp server#
If going through the first part of this post felt like pain and suffering, don’t worry - i felt the same writing it. That’s why it took a month to write. But, at long last we can do something fun.
Let’s start, as usual, with printing the help to make sure our binary is working fine:
llama-server --help
You should see a lot of options. Some of them will be explained here in a bit, some of them you’ll have to research yourself. For now, the only options that are interesting to us are:
-m, --model FNAME model path (default: `models/$filename` with filename from `--hf-file`
or `--model-url` if set, otherwise models/7B/ggml-model-f16.gguf)
(env: LLAMA_ARG_MODEL)
--host HOST ip address to listen (default: 127.0.0.1)
(env: LLAMA_ARG_HOST)
--port PORT port to listen (default: 8080)
(env: LLAMA_ARG_PORT)
Run llama-server with model’s path set to quantized SmolLM2 GGUF file.
If you don’t have anything running on 127.0.0.1:8080, you can leave the host and port on defaults.
Notice that you can also use environmental variables instead of arguments, so you can setup your env and just call llama-server.
llama-server -m SmolLM2.q8.gguf
You should see similar output after running this command:
build: 4182 (ab96610b) with cc (GCC) 14.2.1 20240910 for x86_64-pc-linux-gnu
system info: n_threads = 12, n_threads_batch = 12, total_threads = 24
system_info: n_threads = 12 (n_threads_batch = 12) / 24 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | AARCH64_REPACK = 1 |
main: HTTP server is listening, hostname: 127.0.0.1, port: 8080, http threads: 23
main: loading model
srv load_model: loading model 'SmolLM2.q8.gguf'
llama_model_loader: loaded meta data with 37 key-value pairs and 218 tensors from SmolLM2.q8.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = SmolLM2 1.7B Instruct
llama_model_loader: - kv 3: general.finetune str = Instruct
llama_model_loader: - kv 4: general.basename str = SmolLM2
llama_model_loader: - kv 5: general.size_label str = 1.7B
llama_model_loader: - kv 6: general.license str = apache-2.0
llama_model_loader: - kv 7: general.base_model.count u32 = 1
llama_model_loader: - kv 8: general.base_model.0.name str = SmolLM2 1.7B
llama_model_loader: - kv 9: general.base_model.0.organization str = HuggingFaceTB
llama_model_loader: - kv 10: general.base_model.0.repo_url str = https://huggingface.co/HuggingFaceTB/...
llama_model_loader: - kv 11: general.tags arr[str,4] = ["safetensors", "onnx", "transformers...
llama_model_loader: - kv 12: general.languages arr[str,1] = ["en"]
llama_model_loader: - kv 13: llama.block_count u32 = 24
llama_model_loader: - kv 14: llama.context_length u32 = 8192
llama_model_loader: - kv 15: llama.embedding_length u32 = 2048
llama_model_loader: - kv 16: llama.feed_forward_length u32 = 8192
llama_model_loader: - kv 17: llama.attention.head_count u32 = 32
llama_model_loader: - kv 18: llama.attention.head_count_kv u32 = 32
llama_model_loader: - kv 19: llama.rope.freq_base f32 = 130000.000000
llama_model_loader: - kv 20: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 21: general.file_type u32 = 7
llama_model_loader: - kv 22: llama.vocab_size u32 = 49152
llama_model_loader: - kv 23: llama.rope.dimension_count u32 = 64
llama_model_loader: - kv 24: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 25: tokenizer.ggml.pre str = smollm
llama_model_loader: - kv 26: tokenizer.ggml.tokens arr[str,49152] = ["<|endoftext|>", "<|im_start|>", "<|...
llama_model_loader: - kv 27: tokenizer.ggml.token_type arr[i32,49152] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
llama_model_loader: - kv 28: tokenizer.ggml.merges arr[str,48900] = ["Ġ t", "Ġ a", "i n", "h e", "Ġ Ġ...
llama_model_loader: - kv 29: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 30: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 31: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 32: tokenizer.ggml.padding_token_id u32 = 2
llama_model_loader: - kv 33: tokenizer.chat_template str = {% for message in messages %}{% if lo...
llama_model_loader: - kv 34: tokenizer.ggml.add_space_prefix bool = false
llama_model_loader: - kv 35: tokenizer.ggml.add_bos_token bool = false
llama_model_loader: - kv 36: general.quantization_version u32 = 2
llama_model_loader: - type f32: 49 tensors
llama_model_loader: - type q8_0: 169 tensors
llm_load_vocab: special tokens cache size = 17
llm_load_vocab: token to piece cache size = 0.3170 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 49152
llm_load_print_meta: n_merges = 48900
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 8192
llm_load_print_meta: n_embd = 2048
llm_load_print_meta: n_layer = 24
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_rot = 64
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 64
llm_load_print_meta: n_embd_head_v = 64
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 2048
llm_load_print_meta: n_embd_v_gqa = 2048
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 8192
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 130000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 8192
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: ssm_dt_b_c_rms = 0
llm_load_print_meta: model type = ?B
llm_load_print_meta: model ftype = Q8_0
llm_load_print_meta: model params = 1.71 B
llm_load_print_meta: model size = 1.69 GiB (8.50 BPW)
llm_load_print_meta: general.name = SmolLM2 1.7B Instruct
llm_load_print_meta: BOS token = 1 '<|im_start|>'
llm_load_print_meta: EOS token = 2 '<|im_end|>'
llm_load_print_meta: EOT token = 0 '<|endoftext|>'
llm_load_print_meta: UNK token = 0 '<|endoftext|>'
llm_load_print_meta: PAD token = 2 '<|im_end|>'
llm_load_print_meta: LF token = 143 'Ä'
llm_load_print_meta: EOG token = 0 '<|endoftext|>'
llm_load_print_meta: EOG token = 2 '<|im_end|>'
llm_load_print_meta: max token length = 162
llm_load_tensors: CPU_Mapped model buffer size = 1734.38 MiB
................................................................................................
llama_new_context_with_model: n_seq_max = 1
llama_new_context_with_model: n_ctx = 4096
llama_new_context_with_model: n_ctx_per_seq = 4096
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 130000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: n_ctx_per_seq (4096) < n_ctx_train (8192) -- the full capacity of the model will not be utilized
llama_kv_cache_init: CPU KV buffer size = 768.00 MiB
llama_new_context_with_model: KV self size = 768.00 MiB, K (f16): 384.00 MiB, V (f16): 384.00 MiB
llama_new_context_with_model: CPU output buffer size = 0.19 MiB
llama_new_context_with_model: CPU compute buffer size = 280.01 MiB
llama_new_context_with_model: graph nodes = 774
llama_new_context_with_model: graph splits = 1
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
srv init: initializing slots, n_slots = 1
slot init: id 0 | task -1 | new slot n_ctx_slot = 4096
main: model loaded
main: chat template, built_in: 1, chat_example: '<|im_start|>system
You are a helpful assistant<|im_end|>
<|im_start|>user
Hello<|im_end|>
<|im_start|>assistant
Hi there<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
'
main: server is listening on http://127.0.0.1:8080 - starting the main loop
srv update_slots: all slots are idle
And now we can access the web UI on http://127.0.0.1:8080 or whatever host/port combo you’ve set.
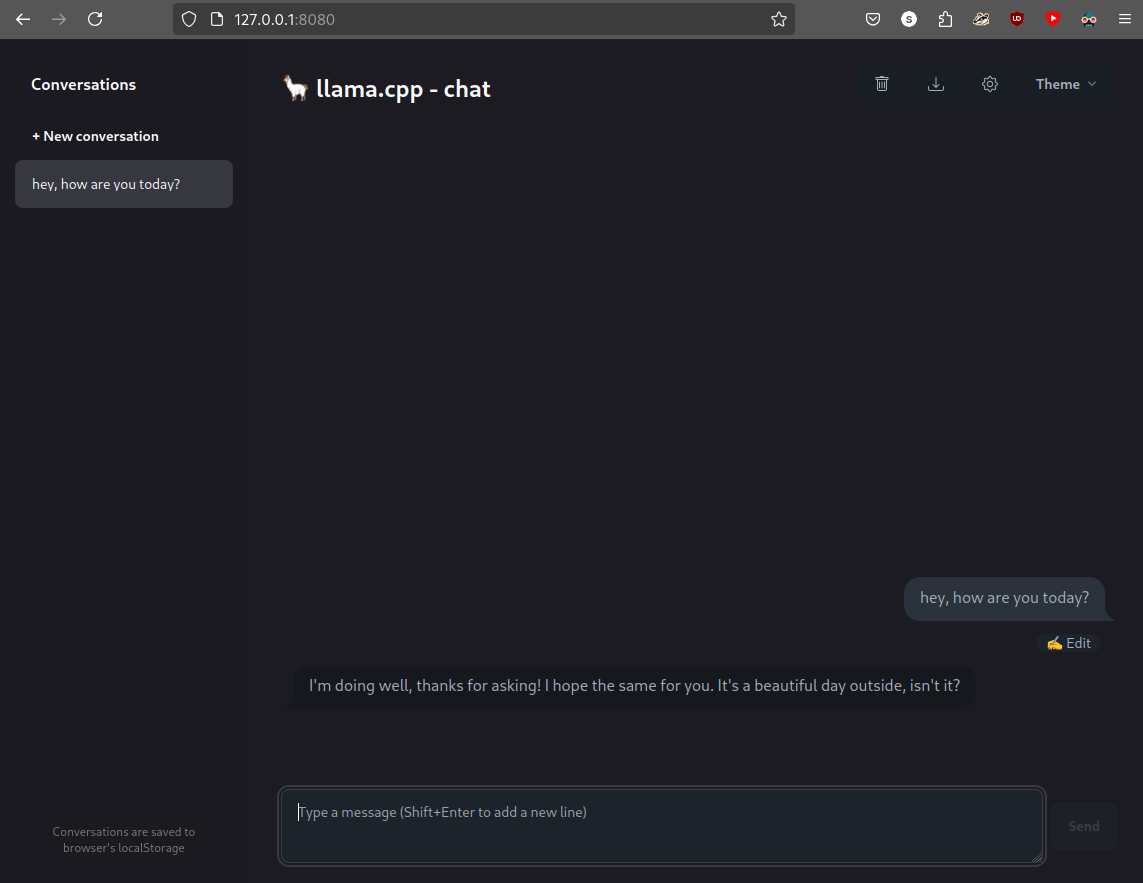
From this point, we can freely chat with the LLM using the web UI, or you can use the OpenAI-compatible API that llama-server provides.
I won’t dig into the API itself here, i’ve written a Python library for it if you’re interested in using it (i’m trying to keep it up-to-date with llama.cpp master, but it might not be all the time).
I recommend looking into the llama-server source code and README for more details about endpoints.
Let’s see what we can do with web UI. On the left, we have list of conversations. Those are stored in browser’s localStorage (as the disclaimer on the bottom-left graciously explains), which means they are persistent even if you restart the browser. Keep in mind that changing the host/port of the server will “clear” those. Current conversation is passed to the LLM as context, and the context size is limited by server settings (we will learn how to tweak it in a second). I recommend making new conversations often, and keeping their context focused on the subject for optimal performance.
On the top-right, we have (from left to right) “remove conversation”, “download conversation” (in JSON format), “configuration” and “Theme” buttons. In the configuration window, we can tweak generation settings for our LLM. Those are currently global, not per-conversation. All of those settings are briefly described below.
llama.cpp server settings#
Web UI provides only a small subset of configuration options we have available, and only those related to LLM samplers.
For the full set, we need to call llama-server --help.
With those options we can drastically improve (or worsen) the behavior of our model and performance of text generation, so it’s worth knowing them.
I won’t explain all of the options listed there, because it would be mostly redundant, but i’ll probably explain most of them in one way of another here.
I’ll try to explain all interesting options though.
One thing that’s also worth mentioning is that most of those parameters are read from the environment.
This is also the case for most other llama.cpp executables, and the parameter names (and environment variables) are the same for them.
Names of those variables are provided in llama-server --help output, i’ll add them to each described option here.
Let’s start with common params section:
--threads/--threads-batch(LLAMA_ARG_THREADS) - amount of CPU threads used by LLM. Default value is -1, which tellsllama.cppto detect the amount of cores in the system. This behavior is probably good enough for most of people, so unless you have exotic hardware setup and you know what you’re doing - leave it on default. If you do have an exotic setup, you may also want to look at other NUMA and offloading-related flags.--ctx-size(LLAMA_ARG_CTX_SIZE) - size of the prompt context. In other words, the amount of tokens that the LLM can remember at once. Increasing the context size also increases the memory requirements for the LLM. Every model has a context size limit, when this argument is set to0,llama.cpptries to use it.--predict(LLAMA_ARG_N_PREDICT) - number of tokens to predict. When LLM generates text, it stops either after generating end-of-message token (when it decides that the generated sentence is over), or after hitting this limit. Default is-1, which makes the LLM generate text ad infinitum. If we want to limit it to context size, we can set it to-2.--batch-size/--ubatch-size(LLAMA_ARG_BATCH/LLAMA_ARG_UBATCH) - amount of tokens fed to the LLM in single processing step. Optimal value of those arguments depends on your hardware, model, and context size - i encourage experimentation, but defaults are probably good enough for start.--flash-attn(LLAMA_ARG_FLASH_ATTN) - Flash attention is an optimization that’s supported by most recent models. Read the linked article for details, in short - enabling it should improve the generation performance for some models.llama.cppwill simply throw a warning when a model that doesn’t support flash attention is loaded, so i keep it on at all times without any issues.--mlock(LLAMA_ARG_MLOCK) - this option is called exactly like Linux function that it uses underneath. On Windows, it uses VirtualLock. If you have enough virtual memory (RAM or VRAM) to load the whole model into, you can use this parameter to prevent OS from swapping it to the hard drive. Enabling it can increase the performance of text generation, but may slow everything else down in return if you hit the virtual memory limit of your machine.--no-mmap(LLAMA_ARG_NO_MMAP) - by default,llama.cppwill map the model to memory (usingmmapon Linux andCreateFileMappingAon Windows). Using this switch will disable this behavior.--gpu-layers(LLAMA_ARG_N_GPU_LAYERS) - if GPU offloading is available, this parameter will set the maximum amount of LLM layers to offload to GPU. Number and size of layers is dependent on the used model. Usually, if we want to load the whole model to GPU, we can set this parameter to some unreasonably large number like 999. For partial offloading, you must experiment yourself.llama.cppmust be built with GPU support, otherwise this option will have no effect. If you have multiple GPUs, you may also want to look at--split-modeand--main-gpuarguments.--model(LLAMA_ARG_MODEL) - path to the GGUF model file.
Most of the options from sampling params section are described in detail below.
Server-specific arguments are:
--no-context-shift(LLAMA_ARG_NO_CONTEXT_SHIFT) - by default, when context is filled up, it will be shifted (“oldest” tokens are discarded in favour of freshly generated ones). This parameter disables that behavior, and it will make the generation stop instead.--cont-batching(LLAMA_ARG_CONT_BATCHING) - continuous batching allows processing prompts in parallel with text generation. This usually improves performance and is enabled by default. You can disable it with--no-cont-batching(LLAMA_ARG_NO_CONT_BATCHING) parameter.--alias(LLAMA_ARG_ALIAS) - Alias for the model name, used by the REST API. Set to model name by default.--host(LLAMA_ARG_HOST) and--port(LLAMA_ARG_PORT) - host and port forllama.cppserver.--slots(LLAMA_ARG_ENDPOINT_SLOTS) - enables/slotsendpoint ofllama.cppserver.--props(LLAMA_ARG_ENDPOINT_PROPS) - enables/propsendpoint ofllama.cppserver.
other llama.cpp tools#
Webserver is not the only thing llama.cpp provides.
There’s few other useful tools hidden in built binaries.
llama-bench#
llama-bench allows us to benchmark the prompt processing and text generation speed of our llama.cpp build for a selected model.
To run an example benchmark, we can simply run the executable with path to selected model.
llama-bench --model selected_model.gguf
llama-bench will try to use optimal llama.cpp configuration for your hardware.
Default settings will try to use full GPU offloading (99 layers) and mmap.
I recommend enabling flash attention manually (with --flash-attn flag, unfortunately llama-bench does not read the environmental variables)
Tweaking prompt length (--n-prompt) and batch sizes (--batch-size/--ubatch-size) may affect the result of prompt processing benchmark.
Tweaking number of tokens to generate (--n-gen) may affect the result of text generation benchmark.
You can also set the number of repetitions with --repetitions argument.
Results for SmolLM2 1.7B Instruct quantized to Q8 w/ flash attention on my setup (CPU only, Ryzen 5900X, DDR4 RAM @3200MHz):
> llama-bench --flash-attn 1 --model ./SmolLM2.q8.gguf
| model | size | params | backend | threads | fa | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | ------: | -: | ------------: | -------------------: |
| llama ?B Q8_0 | 1.69 GiB | 1.71 B | CPU | 12 | 1 | pp512 | 162.54 ± 1.70 |
| llama ?B Q8_0 | 1.69 GiB | 1.71 B | CPU | 12 | 1 | tg128 | 22.50 ± 0.05 |
build: dc223440 (4215)
The table is mostly self-explanatory, except two last columns.
test contains the benchmark identifier, made from two parts.
First two letters define the bench type (pp for prompt processing, tg for text generation).
The number defines the prompt size (for prompt processing benchmark) or amount of generated tokens (for text generation benchmark).
t/s column is the result in tokens processed/generated per second.
There’s also a mystery -pg argument, which can be used to perform mixed prompt processing+text generation test.
For example:
> llama-bench --flash-attn 1 --model ./SmolLM2.q8.gguf -pg 1024,256
| model | size | params | backend | threads | fa | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | ------: | -: | ------------: | -------------------: |
| llama ?B Q8_0 | 1.69 GiB | 1.71 B | CPU | 12 | 1 | pp512 | 165.50 ± 1.95 |
| llama ?B Q8_0 | 1.69 GiB | 1.71 B | CPU | 12 | 1 | tg128 | 22.44 ± 0.01 |
| llama ?B Q8_0 | 1.69 GiB | 1.71 B | CPU | 12 | 1 | pp1024+tg256 | 63.51 ± 4.24 |
build: dc223440 (4215)
This is probably the most realistic benchmark, because as long as you have continuous batching enabled you’ll use the model like that.
llama-cli#
This is a simple CLI interface for the LLM. It allows you to generate a completion for specified prompt, or chat with the LLM.
It shares most arguments with llama-server, except some specific ones:
--prompt- can also be used withllama-server, but here it’s bit more useful. Sets the starting/system prompt for the LLM. Prompt can also be loaded from file by specifying it’s path using--fileor--binary-fileargument.--color- enables colored output, it’s disabled by default.--no-context-shift(LLAMA_ARG_NO_CONTEXT_SHIFT) - does the same thing as inllama-server.--reverse-prompt- when LLM generates a reverse prompt, it stops generation and returns the control over conversation to the user, allowing him to respond. Basically, this is list of stopping words/sentences.--conversation- enables conversation mode by enabling interactive mode and not printing special tokens (like those appearing in chat template) This is probably how you want to use this program.--interactive- enables interactive mode, allowing you to chat with the LLM. In this mode, the generation starts right away and you should set the--promptto get any reasonable output. Alternatively, we can use--interactive-firstto start chatting with control over chat right away.
Here are specific usage examples:
text completion#
> llama-cli --flash-attn --model ./SmolLM2.q8.gguf --prompt "The highest mountain on earth"
build: 4215 (dc223440) with cc (GCC) 14.2.1 20240910 for x86_64-pc-linux-gnu
main: llama backend init
main: load the model and apply lora adapter, if any
llama_model_loader: loaded meta data with 37 key-value pairs and 218 tensors from ./SmolLM2.q8.gguf (version GGUF V3 (latest))
...
llm_load_tensors: CPU_Mapped model buffer size = 1734,38 MiB
................................................................................................
llama_new_context_with_model: n_seq_max = 1
llama_new_context_with_model: n_ctx = 4096
llama_new_context_with_model: n_ctx_per_seq = 4096
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 1
llama_new_context_with_model: freq_base = 130000,0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: n_ctx_per_seq (4096) < n_ctx_train (8192) -- the full capacity of the model will not be utilized
llama_kv_cache_init: CPU KV buffer size = 768,00 MiB
llama_new_context_with_model: KV self size = 768,00 MiB, K (f16): 384,00 MiB, V (f16): 384,00 MiB
llama_new_context_with_model: CPU output buffer size = 0,19 MiB
llama_new_context_with_model: CPU compute buffer size = 104,00 MiB
llama_new_context_with_model: graph nodes = 679
llama_new_context_with_model: graph splits = 1
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
main: llama threadpool init, n_threads = 12
system_info: n_threads = 12 (n_threads_batch = 12) / 24 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | AARCH64_REPACK = 1 |
sampler seed: 2734556630
sampler params:
repeat_last_n = 64, repeat_penalty = 1,000, frequency_penalty = 0,000, presence_penalty = 0,000
dry_multiplier = 0,000, dry_base = 1,750, dry_allowed_length = 2, dry_penalty_last_n = -1
top_k = 40, top_p = 0,950, min_p = 0,050, xtc_probability = 0,000, xtc_threshold = 0,100, typical_p = 1,000, temp = 0,800
mirostat = 0, mirostat_lr = 0,100, mirostat_ent = 5,000
sampler chain: logits -> logit-bias -> penalties -> dry -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist
generate: n_ctx = 4096, n_batch = 2048, n_predict = -1, n_keep = 0
The highest mountain on earth is Mount Everest, which stands at an astonishing 8,848.86 meters (29,031.7 feet) above sea level. Located in the Mahalangur Sharhungtrigangla Range in the Himalayas, it's a marvel of nature that draws adventurers and thrill-seekers from around the globe.
Standing at the base camp, the mountain appears as a majestic giant, its rugged slopes and snow-capped peaks a testament to its formidable presence. The climb to the summit is a grueling challenge that requires immense physical and mental fortitude, as climbers must navigate steep inclines, unpredictable weather, and crevasses.
The ascent begins at Base Camp, a bustling hub of activity, where climbers gather to share stories, exchange tips, and prepare for the climb ahead. From Base Camp, climbers make their way to the South Col, a precarious route that offers breathtaking views of the surrounding landscape. The final push to the summit involves a grueling ascent up the steep and treacherous Lhotse Face, followed by a scramble up the near-vertical wall of the Western Cwm.
Upon reaching the summit, climbers are rewarded with an unforgettable sight: the majestic Himalayan range unfolding before them, with the sun casting a golden glow on the snow. The sense of accomplishment and awe is indescribable, and the experience is etched in the memories of those who have conquered this mighty mountain.
The climb to Everest is not just about reaching the summit; it's an adventure that requires patience, perseverance, and a deep respect for the mountain. Climbers must be prepared to face extreme weather conditions, altitude sickness, and the ever-present risk of accidents or crevasses. Despite these challenges, the allure of Everest remains a powerful draw, inspiring countless individuals to push their limits and push beyond them. [end of text]
llama_perf_sampler_print: sampling time = 12,58 ms / 385 runs ( 0,03 ms per token, 30604,13 tokens per second)
llama_perf_context_print: load time = 318,81 ms
llama_perf_context_print: prompt eval time = 59,26 ms / 5 tokens ( 11,85 ms per token, 84,38 tokens per second)
llama_perf_context_print: eval time = 17797,98 ms / 379 runs ( 46,96 ms per token, 21,29 tokens per second)
llama_perf_context_print: total time = 17891,23 ms / 384 tokens
chat mode#
> llama-cli --flash-attn --model ./SmolLM2.q8.gguf --prompt "You are a helpful assistant" --conversation
build: 4215 (dc223440) with cc (GCC) 14.2.1 20240910 for x86_64-pc-linux-gnu
main: llama backend init
main: load the model and apply lora adapter, if any
llama_model_loader: loaded meta data with 37 key-value pairs and 218 tensors from ./SmolLM2.q8.gguf (version GGUF V3 (latest))
...
llm_load_tensors: CPU_Mapped model buffer size = 1734,38 MiB
................................................................................................
llama_new_context_with_model: n_seq_max = 1
llama_new_context_with_model: n_ctx = 4096
llama_new_context_with_model: n_ctx_per_seq = 4096
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 1
llama_new_context_with_model: freq_base = 130000,0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: n_ctx_per_seq (4096) < n_ctx_train (8192) -- the full capacity of the model will not be utilized
llama_kv_cache_init: CPU KV buffer size = 768,00 MiB
llama_new_context_with_model: KV self size = 768,00 MiB, K (f16): 384,00 MiB, V (f16): 384,00 MiB
llama_new_context_with_model: CPU output buffer size = 0,19 MiB
llama_new_context_with_model: CPU compute buffer size = 104,00 MiB
llama_new_context_with_model: graph nodes = 679
llama_new_context_with_model: graph splits = 1
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
main: llama threadpool init, n_threads = 12
main: chat template example:
<|im_start|>system
You are a helpful assistant<|im_end|>
<|im_start|>user
Hello<|im_end|>
<|im_start|>assistant
Hi there<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
system_info: n_threads = 12 (n_threads_batch = 12) / 24 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | AARCH64_REPACK = 1 |
main: interactive mode on.
sampler seed: 968968654
sampler params:
repeat_last_n = 64, repeat_penalty = 1,000, frequency_penalty = 0,000, presence_penalty = 0,000
dry_multiplier = 0,000, dry_base = 1,750, dry_allowed_length = 2, dry_penalty_last_n = -1
top_k = 40, top_p = 0,950, min_p = 0,050, xtc_probability = 0,000, xtc_threshold = 0,100, typical_p = 1,000, temp = 0,800
mirostat = 0, mirostat_lr = 0,100, mirostat_ent = 5,000
sampler chain: logits -> logit-bias -> penalties -> dry -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist
generate: n_ctx = 4096, n_batch = 2048, n_predict = -1, n_keep = 0
== Running in interactive mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to the AI.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
system
You are a helpful assistant
> hi
Hello! How can I help you today?
>
llama_perf_sampler_print: sampling time = 0,27 ms / 22 runs ( 0,01 ms per token, 80291,97 tokens per second)
llama_perf_context_print: load time = 317,46 ms
llama_perf_context_print: prompt eval time = 2043,02 ms / 22 tokens ( 92,86 ms per token, 10,77 tokens per second)
llama_perf_context_print: eval time = 407,66 ms / 9 runs ( 45,30 ms per token, 22,08 tokens per second)
llama_perf_context_print: total time = 5302,60 ms / 31 tokens
Interrupted by user
building the llama, but better#
All right, now that we know how to use llama.cpp and tweak runtime parameters, let’s learn how to tweak build configuration.
We already set some generic settings in chapter about building the llama.cpp but we haven’t touched any backend-related ones yet.
Back-end for llama.cpp is provided via ggml library (created by the same author!).
This library contains the code for math operations used to run LLMs, and it supports many hardware accelerations that we can enable to get the maximum LLM performance on our hardware.
Let’s start with clearing up the llama.cpp repository (and, optionally, making sure that we have the latest commit):
cd llama.cpp
git clean -xdf
git pull
git submodule update --recursive
Now, we need to generate the build files for a custom backend.
As of writing this, the list of backends supported by ggml library is following:
Metal- acceleration for Apple SiliconAccelerate- BLAS (Basic Linear Algebra Subprograms) acceleration for Mac PCs, enabled by default.OpenBLAS- BLAS acceleration for CPUsBLIS- relatively recently released high-performance BLAS frameworkSYCL- acceleration for Intel GPUs (Data Center Max series, Flex series, Arc series, Built-in GPUs and iGPUs)Intel oneMKL- acceleration for Intel CPUsCUDA- acceleration for Nvidia GPUsMUSA- acceleration for Moore Threads GPUshipBLAS- BLAS acceleration for AMD GPUsVulkan- generic acceleration for GPUsCANN- acceleration for Ascend NPU
As we can see, there’s something for everyone.
It’s good to note here that llama.cpp also supports Android!
My backend selection recommendation is following:
- Users without GPUs should try
Intel oneMKLin case of Intel CPUs, orBLIS/OpenBLAS. - Users with Nvidia GPUs should use
CUDAorVulkan - Users with AMD GPUs should use
VulkanorROCm(order important here, ROCm was bugged last time i’ve used it) - Users with Intel GPUs should use
SYCLorVulkan
As we can see, Vulkan is the most generic option for GPU acceleration and i believe it’s the simplest to build for, so i’ll explain in detail how to do that.
Doesn’t matter whether you’re Nvidia, AMD or Intel graphics user - Vulkan implementation should work on most (if not all) of their GPUs, as long as they’re reasonably modern.
The build process for every backend is very similar - install the necessary dependencies, generate the llama.cpp build files with proper flag to enable the specific backend, and build it.
Oh, and don’t worry about Python and it’s dependencies.
The performance of model conversion scripts is not limited by pytorch, so there’s no point in installing CUDA/ROCm versions.
Before generating the build file, we need to install Vulkan SDK.
On Windows, it’s easiest to do via MSYS. That’s why i’ve recommended using it at the beginning. I have tried installing it directly on Windows, but encountered issues that i haven’t seen when using MSYS - so, obviously, MSYS is a better option. Run this command in MSYS (make sure to use UCRT runtime) to install the required dependencies:
pacman -S git \
mingw-w64-ucrt-x86_64-gcc \
mingw-w64-ucrt-x86_64-cmake \
mingw-w64-ucrt-x86_64-vulkan-devel \
mingw-w64-ucrt-x86_64-shaderc
If you really don’t want to use MSYS, i recommend following the docs
On Linux, i recommend installing Vulkan SDK using the package manager. If it’s not in package manager of your distro, i assume you know what you’re doing and how to install it manually.
Afterwards, we can generate the build files.
To enable Vulkan back-end, we need to set GGML_VULKAN variable to ON.
Replace /your/install/dir with custom installation directory, if you want one - otherwise remove this variable:
cmake -S . -B build -G Ninja -DGGML_VULKAN=ON -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/your/install/dir -DLLAMA_BUILD_TESTS=OFF -DLLAMA_BUILD_EXAMPLES=ON -DLLAMA_BUILD_SERVER=ON
and build/install the binaries (replace X with amount of cores in your system):
cmake --build build --config Release -j X
cmake --install build --config Release
Don’t mind the warnings you’ll see, i get them too.
Now our llama.cpp binaries should be able to use our GPU.
We can test it by running llama-server or llama-cli with --list-devices argument:
> llama-cli --list-devices
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = AMD Radeon RX 7900 XT (AMD open-source driver) | uma: 0 | fp16: 1 | warp size: 64
Available devices:
Vulkan0: AMD Radeon RX 7900 XT (20464 MiB, 20464 MiB free)
Running that command previously would print an empty list:
> llama-cli --list-devices
Available devices:
Remember the llama-bench results i’ve got previously on CPU build?
This is them now:
> llama-bench --flash-attn 1 --model ./SmolLM2.q8.gguf -pg 1024,256
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = AMD Radeon RX 7900 XT (AMD open-source driver) | uma: 0 | fp16: 1 | warp size: 64
| model | size | params | backend | ngl | fa | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | -: | ------------: | -------------------: |
ggml_vulkan: Compiling shaders..............................Done!
| llama ?B Q8_0 | 1.69 GiB | 1.71 B | Vulkan | 99 | 1 | pp512 | 880.55 ± 5.30 |
| llama ?B Q8_0 | 1.69 GiB | 1.71 B | Vulkan | 99 | 1 | tg128 | 89.78 ± 1.66 |
| llama ?B Q8_0 | 1.69 GiB | 1.71 B | Vulkan | 99 | 1 | pp1024+tg256 | 115.25 ± 0.83 |
Now, that’s some good shit right here. Prompt processing speed has increased from ~165 to ~880 tokens per second (5.3x faster). Text generation - from ~22 to ~90 tokens per second (4x faster). Mixed text processing went up from ~63 to ~115 tokens per second (1.8x faster). All of this due to the fact that i’ve switched to correct backend.
need better CPU support?#
Vulkan back-end is a good generic way of running the LLMs on GPU.
But what if you don’t have one, and still want to get the maximum performance out of your hardware?
Fortunately, ggml library has support for optional CPU instruction sets that provide faster math operations for LLMs, like AVX.
All the configuration options for ggml library are defined in ggml/CMakeLists.txt file of llama.cpp repo.
You set them just like you did when building Vulkan, -DVARIABLE_NAME=VALUE when calling cmake for project generation.
I’m gonna list CPU-related ones here, and explain what they do and when you should use them (if i know that).
This list may become outdated, ping me somewhere when ggml gets updated and i don’t notice the change!
You should still double-check and validate this list with latest CMakeLists.txt of ggml.
To quickly check which instruction sets your CPU supports, i recommend HWInfo
GGML_CPU- enables CPU back-end. This is enabled by default and usually should not be changed, even when GPU back-end is enabled.GGML_CPU_HBM- enablesmemkindallocator, mostly for systems with CPU HBM memory.GGML_CPU_AARCH64- enables support for AARCH64 (Armv8-A or newer) architecture.GGML_AVX- enables AVX support. If you’re not cross-compiling, should be enabled by default - most modern CPUs support it.GGML_AVX_VNNI- enables AVX-VNNI support. This is a sub-set of AVX instructions introduced in Intel’s Alder Lake (Q4 2021) and AMD Zen 5 (Q3 2024) CPUs or newer. Enable it if your CPU supports it.GGML_AVX2- similar toGGML_AVX, also enabled by default if not cross-compiling.GGML_AVX512- enables AVX512F support. Check the linked article for the list of supported CPUs. Enable if supported by your CPU.GGML_AVX512_VBMI/VNNI/BF16- those three options control the optimizations for specific AVX512 subsets. Article linked above also provides info about support of those subsets, so enable it accordingly to your hardware.GGML_LASX/LSX- enables support for LoongArch (Loongson CPUs)GGML_RVV- enables support for RISC-V Vector Extension, affects only supported RISC-V CPUs.GGML_SVE- enables support for ARM Scalable Vector Extensions. Available on some ARM CPUs, like Armv9 Cortex-A510.
Following options are not supported under MSVC (another reason to not use it):
GGML_FMA- enables optimizations for FMA instruction set, every modern CPU should support them and it’s enabled by default if not cross-compiling.GGML_F16C- enables optimizations for F16C instruction set, similarly to FMA - every modern CPU supports it, enabled by default when not cross-compiling.GGML_AMX_TILE/INT8/BF16- enables support for Intel’s Advanced Matrix Extensions. This is available only on recent Xeon CPUs.
LLM configuration options explained#
This will be a relatively long and very informational part full of boring explanations. But - it’s a good knowledge to have when playing with LLMs.
how does LLM generate text?#
Prompt
Everything starts with a prompt. Prompt can be a simple raw string that we want the LLM to complete for us, or it can be an elaborate construction that allows the LLM to chat or use external tools. Whatever we put in it, it’s usually in human-readable format with special “tags” (usually similar to XML tags) used for separating the parts of the prompt.
We’ve already seen an example of a prompt used for chat completion, provided by
llama-server:<|im_start|>system You are a helpful assistant<|im_end|> <|im_start|>user Hello<|im_end|> <|im_start|>assistant Hi there<|im_end|> <|im_start|>user How are you?<|im_end|> <|im_start|>assistant(if you’re wondering what are those funny <| and |> symbols - those are ligatures from Fira Code font made out of
|,>and<characters)Tokenization
The LLM does not understand the human language like we do. We use words and punctuation marks to form sentences - LLMs use tokens that can be understood as an equivalent to those. First step in text generation is breaking the language barrier by performing prompt tokenization. Tokenization is a process of translating input text (in human-readable format) into an array of tokens that can be processed by an LLM. Tokens are simple numeric values, and with a vocabulary they can be easily mapped to their string representations (at least in case of BPE models, don’t know about others). In fact, that vocabulary is available in SmolLM2 repository, in
tokenizer.jsonfile! That file also contains some metadata for special tokens that have special meaning for the LLM. Some of those tokens represent meta things, like start and end of a message. Other can allow the LLM to chat with the user by providing tags for separating parts of conversation (system prompt, user messages, LLM responses). I’ve also seen tool calling capabilities in LLM templates, which in theory should allow the LLM to use external tools, but i haven’t tested them yet (check out Qwen2.5 and CodeQwen2.5 for example models with those functions).We can use
llama-serverAPI to tokenize some text and see how it looks after being translated. Hope you’ve gotcurl.curl -X POST -H "Content-Type: application/json" -d '{"content": "hello world! this is an example message!"}' http://127.0.0.1:8080/tokenizeFor SmolLM2, the response should be following:
{"tokens":[28120,905,17,451,314,1183,3714,17]}Which we can very roughly translate to:
- 28120 - hello
- 905 - world
- 17 - !
- 451 - this
- 314 - is
- 354 - an
- 1183 - example
- 3714 - message
- 17 - !
We can pass this JSON back to
/detokenizeendpoint to get our original text back:curl -X POST -H "Content-Type: application/json" -d '{"tokens": [28120,905,17,451,314,354,1183,3714,17]}' http://127.0.0.1:8080/detokenize{"content":"hello world! this is an example message!"}Dank Magick (feeding the beast)
I honestly don’t know what exactly happens in this step, but i’ll try my best to explain it in simple and very approximate terms. The input is the tokenized prompt. This prompt is fed to the LLM, and the digestion process takes a lot of processing time due to the insane amount of matrix operations that must be performed to satisfy the digital beast. After the prompt is digested, the LLM starts “talking” to us. LLM “talks” by outputting the probability distribution for all the tokens in it’s dictionary. This distribution is a list of pairs containing the token value and it’s probability to be used as the next one. Now, in theory we could use a single token with the highest probability and be done with generation, but that’s not the best way of doing things.
Token sampling
This is probably the most interesting step for us, because we can control it’s every single parameter. As usual, i advise caution when working with raw output from demons - digital or not, it may result in unexpected stuff happening when handled incorrectly. Samplers are used to choose the “best” token from the raw LLM output. They work by trimming down all the available tokens to a single one. Note that not every sampler will do that directly (for example, Top-K picks K tokens), but in the end of tokenization, the result is a single token.
Detokenization
Generated tokens must be converted back to human-readable form, so a detokenization must take place. This is the last step. Hooray, we tamed the digital beast and forced it to talk. I have previously feared the consequences this could bring upon the humanity, but here we are, 373 1457 260 970 1041 3935.
list of LLM configuration options and samplers available in llama.cpp#
- System Message - Usually, conversations with LLMs start with a “system” message that tells the LLM how to behave. This is probably the easiest-to-use tool that can drastically change the behavior of a model. My recommendation is to put as much useful informations and precise behavior descriptions for your application as possible, to maximize the quality of LLM output. You may think that giving the digital demon maximum amount of knowledge may lead to bad things happening, but our reality haven’t collapsed yet so i think we’re good for now.
- Temperature - per
llama.cppdocs “Controls the randomness of the generated text by affecting the probability distribution of the output tokens. Higher = more random, lower = more focused”. I don’t have anything to add here, it controls the “creativity” of an LLM. High values result in more random and “creative” output, but overcooking the beast may result in hallucinations, and - in certain scenarios - screams that will destroy your sanity. Keep it in 0.2-2.0 range for a start, and keep it positive and non-zero. - Dynamic temperature - Dynamic temperature sampling is an addition to temperature sampler.
The linked article describes it in detail, and it’s pretty short so i strongly recommend reading it - i can’t really do a better job explaining it.
There’s also the reddit post with more explanations from the algorithm’s author.
However, in case the article goes down - the short explanation of this algorithm is: it tweaks the temperature of generated tokens based on their entropy.
Entropy here can be understood as inverse of LLMs confidence in generated tokens.
Lower entropy means that the LLM is more confident in it’s predictions, and therefore the temperature of tokens with low entropy should also be low.
High entropy works the other way around.
Effectively, this sampling can encourage creativity while preventing hallucinations at higher temperatures.
I strongly recommend testing it out, as it’s usually disabled by default.
It may require some additional tweaks to other samplers when enabled, to produce optimal results.
The parameters of dynamic temperature sampler are:
- Dynatemp range - the range of dynamic temperature to be added/subtracted
- Dynatemp exponent - changing the exponent changes the dynamic temperature in following way (figure shamelessly stolen from previously linked reentry article):
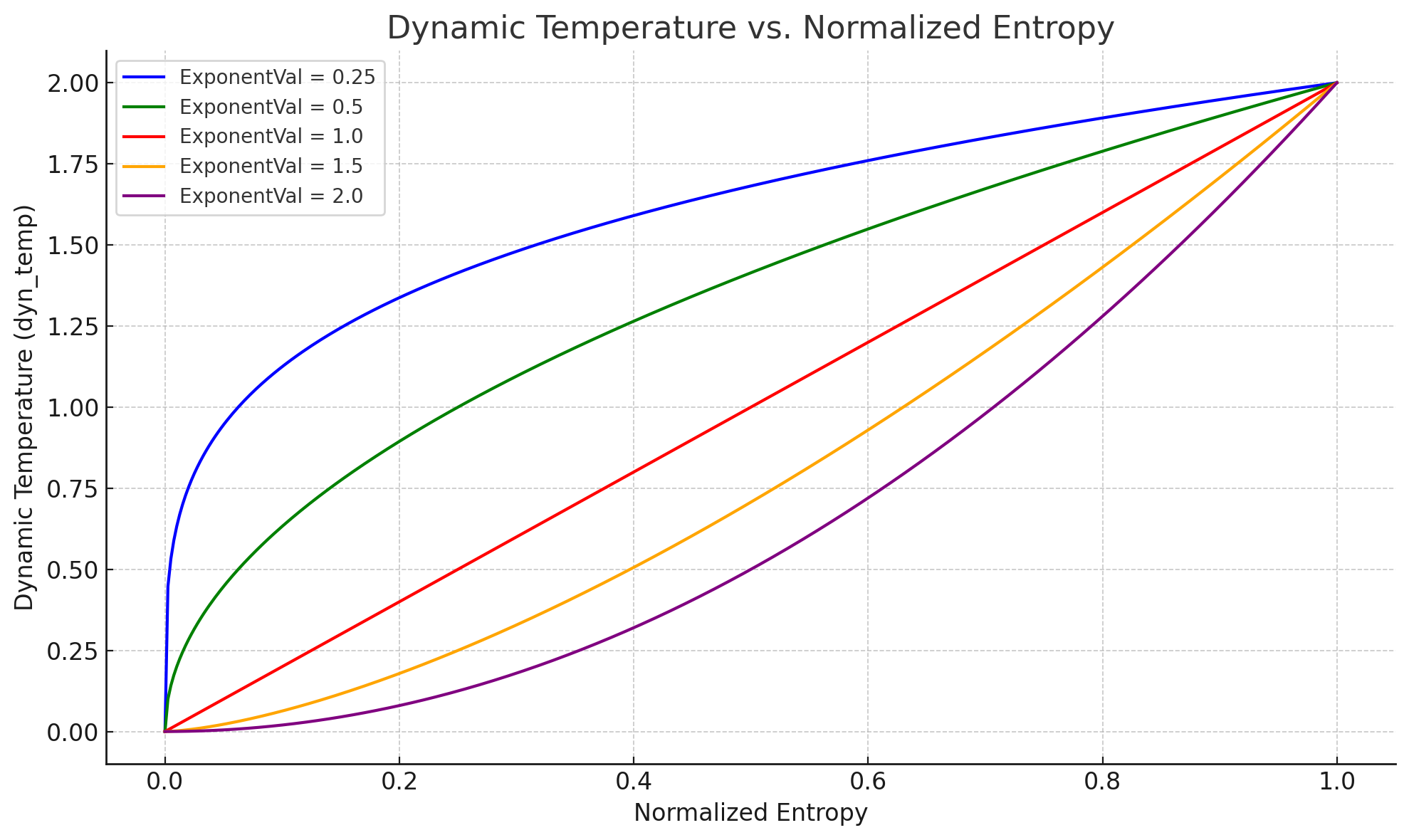
- Top-K - Top-K sampling is a fancy name for “keep only
Kmost probable tokens” algorithm. Higher values can result in more diverse text, because there’s more tokens to choose from when generating responses. - Top-P - Top-P sampling, also called nucleus sampling, per
llama.cppdocs “Limits the tokens to those that together have a cumulative probability of at leastp”. In human language, it means that the Top-P sampler takes a list of tokens and their probabilities as an input (note that the sum of their cumulative probabilities is by definition equal to 1), and returns tokens with highest probabilities from that list until the sum of their cumulative probabilities is greater or equal top. Or, in other words,pvalue changes the % of tokens returned by the Top-P sampler. For example, whenpis equal to 0.7, the sampler will return 70% of input tokens with highest probabilities. There’s a pretty good article about temperature, Top-K and Top-P sampling that i’ve found and can recommend if you wanna know more. - Min-P - Min-P sampling, per
llama.cppdocs “Limits tokens based on the minimum probability for a token to be considered, relative to the probability of the most likely token”. There’s a paper explaining this algorithm (it contains loads of citations for other LLM-related stuff too, good read). Figure 1 from this paper nicely shows what each of the sampling algorithms does to probability distribution of tokens: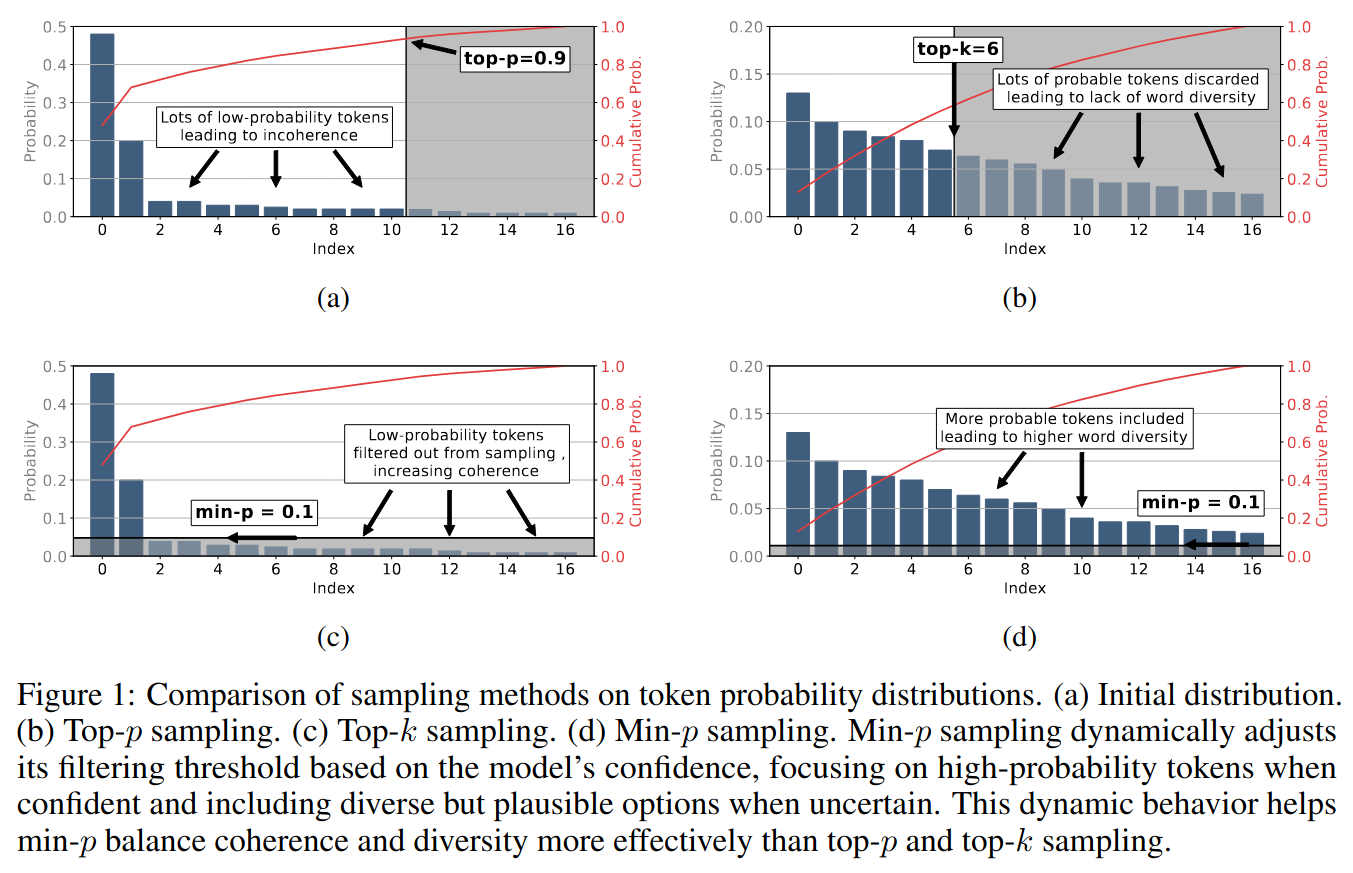
- Exclude Top Choices (XTC) - This is a funky one, because it works a bit differently from most other samplers.
Quoting the author, Instead of pruning the least likely tokens, under certain circumstances, it removes the most likely tokens from consideration.
Detailed description can be found in the PR with implementation.
I recommend reading it, because i really can’t come up with anything better in few sentences, it’s a really good explanation.
I can, however, steal this image from the linked PR to show you more-or-less what XTC does:
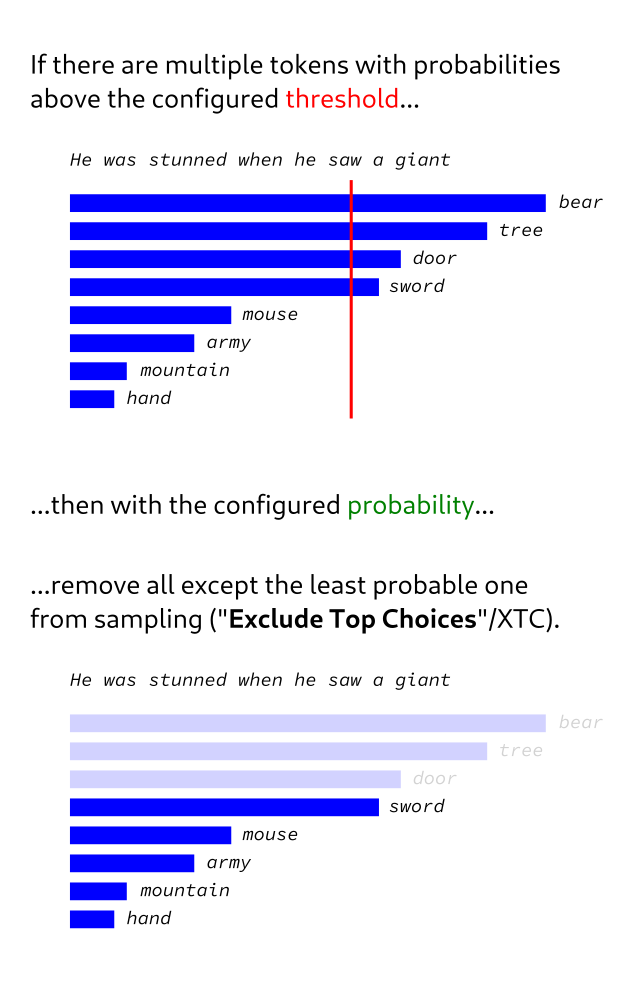 The parameters for XTC sampler are:
The parameters for XTC sampler are:- XTC threshold - probability cutoff threshold for top tokens, in (0, 1) range.
- XTC probability - probability of XTC sampling being applied in [0, 1] range, where 0 = XTC disabled, 1 = XTC always enabled.
- Locally typical sampling (typical-P) - per
llama.cppdocs “Sorts and limits tokens based on the difference between log-probability and entropy”. I… honestly don’t know how exactly it works. I tried reading the linked paper, but i lack the mental capacity to understand it enough to describe it back. Some people on Reddit also have the same issue, so i recommend going there and reading the comments. I haven’t used that sampling much, so i can’t really say anything about it from experience either, so - moving on. - DRY - This sampler is used to prevent unwanted token repetition.
Simplifying, it tries to detect repeating token sequences in generated text and reduces the probabilities of tokens that will create repetitions.
As usual, i recommend reading the linked PR for detailed explanation, and as usual i’ve stolen a figure from it that shows what DRY does:
 I’ll also quote a short explanation of this sampler:
The penalty for a token is calculated as
I’ll also quote a short explanation of this sampler:
The penalty for a token is calculated as multiplier * base ^ (n - allowed_length), wherenis the length of the sequence before that token that matches the end of the input, andmultiplier,base, andallowed_lengthare configurable parameters. If the length of the matching sequence is less thanallowed_length, no penalty is applied. The parameters for DRY sampler are:- DRY multiplier - see explanation above
- DRY base - see explanation above
- DRY allowed length - see explanation above. Quoting
llama.cppdocs: Tokens that extend repetition beyond this receive exponentially increasing penalty. - DRY penalty last N - how many tokens should be scanned for repetition. -1 = whole context, 0 = disabled.
- DRY sequence breakers - characters that are used as separators for parts of sentences considered for DRY. Defaults for
llama.cppare('\n', ':', '"', '*').
- Mirostat - is a funky sampling algorithm that overrides Top-K, Top-P and Typical-P samplers.
It’s an alternative sampler that produces text with controlled perplexity (entropy), which means that we can control how certain the model should be in it’s predictions.
This comes without side-effects of generating repeated text (as it happens in low perplexity scenarios) or incoherent output (as it happens in high perplexity scenarios).
The configuration parameters for Mirostat are:
- Mirostat version - 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0.
- Mirostat learning rate (η, eta) - specifies how fast the model converges to desired perplexity.
- Mirostat target entropy (τ, tau) - the desired perplexity. Depending on the model, it should not be too high, otherwise you may degrade it’s performance.
- Max tokens - i think that’s pretty self-explanatory. -1 makes the LLM generate until it decides it’s end of the sentence (by returning end-of-sentence token), or the context is full.
- Repetition penalty - Repetition penalty algorithm (not to be mistaken with DRY) simply reduces the chance that tokens that are already in the generated text will be used again.
Usually the repetition penalty algorithm is restricted to
Nlast tokens of the context. In case ofllama.cpp(i’ll simplify a bit), it works like that: first, it creates a frequency map occurrences for lastNtokens. Then, the current logit bias for each token is divided byrepeat_penaltyvalue. By default it’s usually set to 1.0, so to enable repetition penalty it should be set to >1. Finally, frequency and presence penalties are applied based on the frequency map. The penalty for each token is equal to(token_count * frequency_penalty) + (presence_penalty if token_count > 0). The penalty is represented as logit bias, which can be in [-100, 100] range. Negative values reduce the probability of token appearing in output, while positive increase it. The configuration parameters for repetition penalty are:- Repeat last N - Amount of tokens from the end of the context to consider for repetition penalty.
- Repeat penalty -
repeat_penaltyargument described above, if equal to1.0then the repetition penalty is disabled. - Presence penalty -
presence_penaltyargument from the equation above. - Frequency penalty -
frequency_penaltyargument from the equation above.
Additional literature:
In Other sampler settings we can find sampling queue configuration. As i’ve mentioned earlier, the samplers are applied in a chain. Here, we can configure the order of their application, and select which are used. The setting uses short names for samplers, the mapping is following:
d- DRYk- Top-Ky- Typical-Pp- Top-Pm- Min-Px- Exclude Top Choices (XTC)t- Temperature
Some samplers and settings i’ve listed above may be missing from web UI configuration (like Mirostat), but they all can be configured via environmental variables, CLI arguments for llama.cpp binaries, or llama.cpp server API.
final thoughts#
That is a long post, damn.
I have started writing this post at the end of October.
It’s almost December now.
During that time, multiple new models have been released - including SmolLM2, fun fact - i have originally planned to use Llama 3.2 3B.
The speed at which the LLM community moves and releases new stuff is absolutely incredible, but thankfully llama.cpp is relatively stable now.
I hope the knowledge i’ve gathered in this post will be useful and inspiring to the readers, and will allow them to play with LLMs freely in their homes.
That’s it, i’m tired.
I’m releasing that shit into the wild.
Suggestions for next posts are welcome, for now i intend to make some scripts for automated benchmarks w/ llama-bench and gather some data.
I’ll try to keep this post up-to-date and maybe add some stuff if it’s requested.
Questions are welcome too, preferably in the comments section.
Have a nice one.
bonus: where to find models, and some recommendations#
My favorite site for finding models and comparing them is LLM Explorer. It’s basically a search engine for models. The UI is not exactly great but it’s good enough, it has the most comprehensive list of LLMs i’ve seen, and lots of search options.
As for my recommendations, some relatively recent models i’ve tried that made a positive impression upon me are:
- Google Gemma 2 9B SimPO - a fine-tune of Google Gemma model. Gemma models are pretty interesting, and their responses are noticeably different from other models.
- Meta Llama 3.1/3.2 - i recommend trying out Llama 3.1 8B Instruct, as it’s the default go-to model for most LLM applications. There’s also many finetunes and abliterated versions that don’t have any built-in restrictions available publicly.
- Microsoft Phi 3.5 - a series of models from Microsoft. Most of them are small, but there’s also big MoE (Mixture of Experts) version available.
- Qwen/CodeQwen 2.5 - series of models from Alibaba, currently one of the best open-source models available. At the moment of writing this, CodeQwen 14B is my daily driver model.
post-mortem#
I’ve shared this post on Reddit and after getting the feedback, i managed to fix multiple issues with this post. Thanks! I’m currently at the process of refactors, so many small things may change, and many other small things may be added in following days. I’ll update this section when i’m finished.
- 03.12.2024 - Updated the part about LLM text generation. I have made some mistakes there, so i’ve updated my knowledge and the post. Thanks /r/AbaGuy17, /r/Oscylator and others for pointing stuff up.
- 10.12.2024 - Updated the back-end part, added info about CPU optimizations.